Execution Model¶
Luigi has a quite simple model for execution and triggering.
Workers and task execution¶
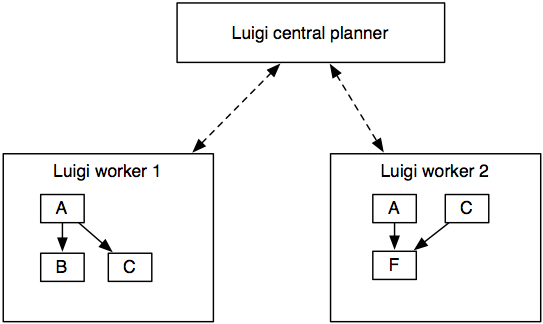
The most important aspect is that no execution is transferred. When you run a Luigi workflow, the worker schedules all tasks, and also executes the tasks within the process.
The benefit of this scheme is that it’s super easy to debug since all execution takes place in the process. It also makes deployment a non-event. During development, you typically run the Luigi workflow from the command line, whereas when you deploy it, you can trigger it using crontab or any other scheduler.
The downside is that Luigi doesn’t give you scalability for free. In practice this is not a problem until you start running thousands of tasks.
Isn’t the point of Luigi to automate and schedule these workflows? To some extent. Luigi helps you encode the dependencies of tasks and build up chains. Furthermore, Luigi’s scheduler makes sure that there’s a centralized view of the dependency graph and that the same job will not be executed by multiple workers simultaneously.
Scheduler¶
A client only starts the run() method of a task when the single-threaded
central scheduler has permitted it. Since the number of tasks is usually very
small (in comparison with the petabytes of data one task is processing), we
can afford the convenience of a simple centralised server.
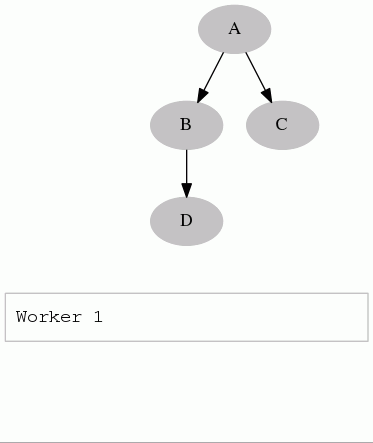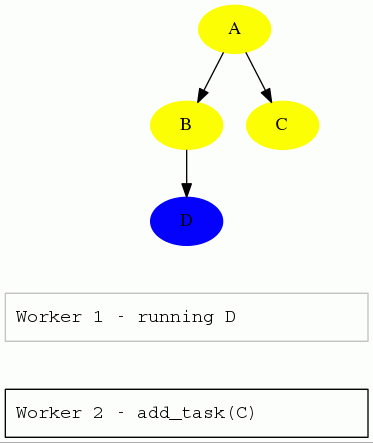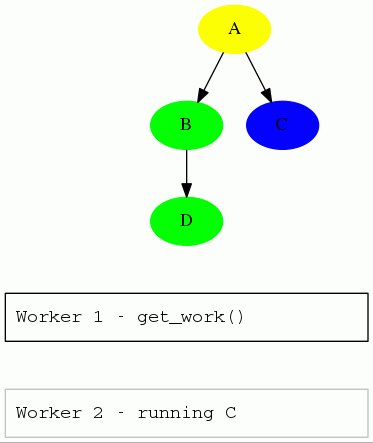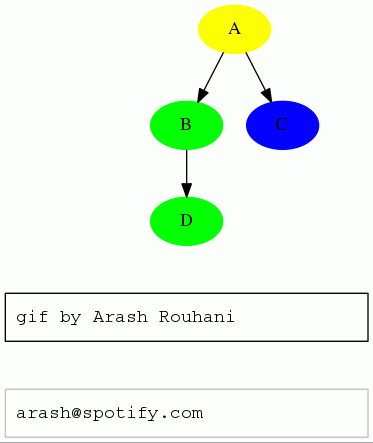
The gif is from this presentation, which is about the client and server interaction.
Triggering tasks¶
Luigi does not include its own triggering, so you have to rely on an external scheduler such as crontab to actually trigger the workflows.
In practice, it’s not a big hurdle because Luigi avoids all the mess typically caused by it. Scheduling a complex workflow is fairly trivial using eg. crontab.
In the future, Luigi might implement its own triggering. The dependency on crontab (or any external triggering mechanism) is a bit awkward and it would be nice to avoid.
Trigger example¶
For instance, if you have an external data dump that arrives every day and that your workflow depends on it, you write a workflow that depends on this data dump. Crontab can then trigger this workflow every minute to check if the data has arrived. If it has, it will run the full dependency graph.
# my_tasks.py
class DataDump(luigi.ExternalTask):
date = luigi.DateParameter()
def output(self): return luigi.contrib.hdfs.HdfsTarget(self.date.strftime('/var/log/dump/%Y-%m-%d.txt'))
class AggregationTask(luigi.Task):
date = luigi.DateParameter()
window = luigi.IntParameter()
def requires(self): return [DataDump(self.date - datetime.timedelta(i)) for i in xrange(self.window)]
def run(self): run_some_cool_stuff(self.input())
def output(self): return luigi.contrib.hdfs.HdfsTarget('/aggregated-%s-%d' % (self.date, self.window))
class RunAll(luigi.Task):
''' Dummy task that triggers execution of a other tasks'''
def requires(self):
for window in [3, 7, 14]:
for d in xrange(10): # guarantee that aggregations were run for the past 10 days
yield AggregationTask(datetime.date.today() - datetime.timedelta(d), window)
In your cronline you would then have something like
30 0 * * * my-user luigi RunAll --module my_tasks
You can trigger this as much as you want from crontab, and
even across multiple machines, because
the central scheduler will make sure at most one of each AggregationTask task is run simultaneously.
Note that this might actually mean multiple tasks can be run because
there are instances with different parameters, and
this can give you some form of parallelization
(eg. AggregationTask(2013-01-09) might run in parallel with AggregationTask(2013-01-08)).
Of course,
some Task types (eg. HadoopJobTask) can transfer execution to other places, but
this is up to each Task to define.
