Tasks
Tasks are where the execution takes place. Tasks depend on each other and output targets.
An outline of how a task can look like:
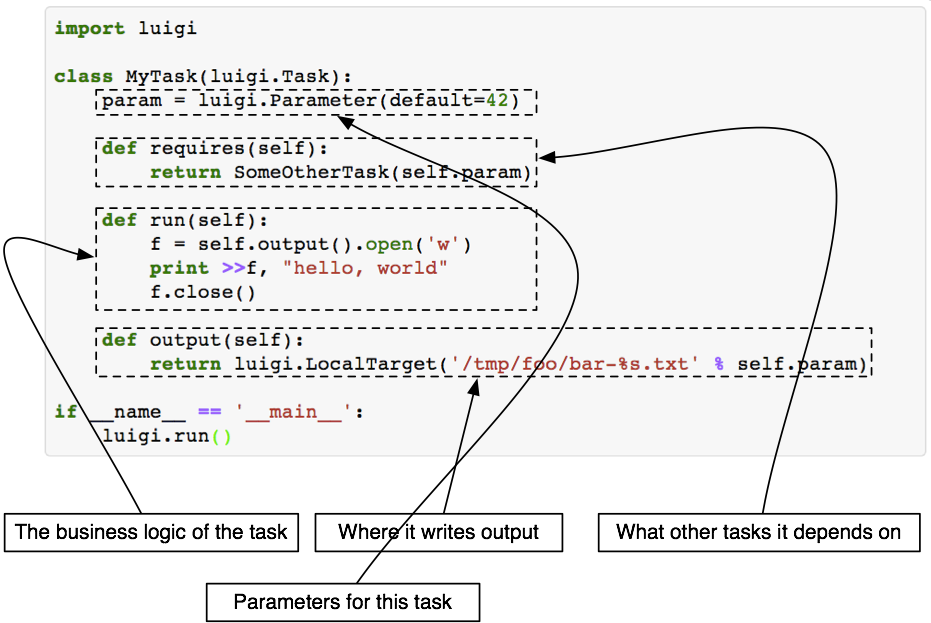
Task.requires
The requires() method is used to specify dependencies on other Task object,
which might even be of the same class.
For instance, an example implementation could be
def requires(self):
return OtherTask(self.date), DailyReport(self.date - datetime.timedelta(1))
In this case, the DailyReport task depends on two inputs created earlier, one of which is the same class. requires can return other Tasks in any way wrapped up within dicts/lists/tuples/etc.
Requiring another Task
Note that requires() can not return a Target object.
If you have a simple Target object that is created externally
you can wrap it in a Task class like this:
class LogFiles(luigi.ExternalTask):
def output(self):
return luigi.contrib.hdfs.HdfsTarget('/log')
This also makes it easier to add parameters:
class LogFiles(luigi.ExternalTask):
date = luigi.DateParameter()
def output(self):
return luigi.contrib.hdfs.HdfsTarget(self.date.strftime('/log/%Y-%m-%d'))
Task.output
The output() method returns one or more Target objects.
Similarly to requires, you can return them wrapped up in any way that’s convenient for you.
However we recommend that any Task only return one single Target in output.
If multiple outputs are returned,
atomicity will be lost unless the Task itself can ensure that each Target is atomically created.
(If atomicity is not of concern, then it is safe to return multiple Target objects.)
class DailyReport(luigi.Task):
date = luigi.DateParameter()
def output(self):
return luigi.contrib.hdfs.HdfsTarget(self.date.strftime('/reports/%Y-%m-%d'))
# ...
Task.run
The run() method now contains the actual code that is run.
When you are using Task.requires and Task.run Luigi breaks down everything into two stages.
First it figures out all dependencies between tasks,
then it runs everything.
The input() method is an internal helper method that just replaces all Task objects in requires
with their corresponding output.
An example:
class GenerateWords(luigi.Task):
def output(self):
return luigi.LocalTarget('words.txt')
def run(self):
# write a dummy list of words to output file
words = [
'apple',
'banana',
'grapefruit'
]
with self.output().open('w') as f:
for word in words:
f.write('{word}\n'.format(word=word))
class CountLetters(luigi.Task):
def requires(self):
return GenerateWords()
def output(self):
return luigi.LocalTarget('letter_counts.txt')
def run(self):
# read in file as list
with self.input().open('r') as infile:
words = infile.read().splitlines()
# write each word to output file with its corresponding letter count
with self.output().open('w') as outfile:
for word in words:
outfile.write(
'{word} | {letter_count}\n'.format(
word=word,
letter_count=len(word)
)
)
It’s useful to note that if you’re writing to a binary file, Luigi automatically
strips the 'b' flag due to how atomic writes/reads work. In order to write a binary
file, such as a pickle file, you should instead use format=Nop when calling
LocalTarget. Following the above example:
from luigi.format import Nop
class GenerateWords(luigi.Task):
def output(self):
return luigi.LocalTarget('words.pckl', format=Nop)
def run(self):
import pickle
# write a dummy list of words to output file
words = [
'apple',
'banana',
'grapefruit'
]
with self.output().open('w') as f:
pickle.dump(words, f)
It is your responsibility to ensure that after running run(), the task is
complete, i.e. complete() returns True. Unless you have overridden
complete(), run() should generate all the targets
defined as outputs. Luigi verifies that you adhere to the contract before running downstream
dependencies, and reports Unfulfilled dependencies at run time if a violation is detected.
Task.input
As seen in the example above, input() is a wrapper around Task.requires that
returns the corresponding Target objects instead of Task objects.
Anything returned by Task.requires will be transformed, including lists,
nested dicts, etc.
This can be useful if you have many dependencies:
class TaskWithManyInputs(luigi.Task):
def requires(self):
return {'a': TaskA(), 'b': [TaskB(i) for i in xrange(100)]}
def run(self):
f = self.input()['a'].open('r')
g = [y.open('r') for y in self.input()['b']]
Dynamic dependencies
Sometimes you might not know exactly what other tasks to depend on until runtime.
In that case, Luigi provides a mechanism to specify dynamic dependencies.
If you yield another Task in the Task.run method,
the current task will be suspended and the other task will be run.
You can also yield a list of tasks.
class MyTask(luigi.Task):
def run(self):
other_target = yield OtherTask()
# dynamic dependencies resolve into targets
f = other_target.open('r')
This mechanism is an alternative to Task.requires in case
you are not able to build up the full dependency graph before running the task.
It does come with some constraints:
the Task.run method will resume from scratch each time a new task is yielded.
In other words, you should make sure your Task.run method is idempotent.
(This is good practice for all Tasks in Luigi, but especially so for tasks with dynamic dependencies).
As this might entail redundant calls to tasks’ complete() methods,
you should consider setting the “cache_task_completion” option in the [worker].
To further control how dynamic task requirements are handled internally by worker nodes,
there is also the option to wrap dependent tasks by DynamicRequirements.
For an example of a workflow using dynamic dependencies, see examples/dynamic_requirements.py.
Task status tracking
For long-running or remote tasks it is convenient to see extended status information not only on the command line or in your logs but also in the GUI of the central scheduler. Luigi implements dynamic status messages, progress bar and tracking urls which may point to an external monitoring system. You can set this information using callbacks within Task.run:
class MyTask(luigi.Task):
def run(self):
# set a tracking url
self.set_tracking_url("http://...")
# set status messages during the workload
for i in range(100):
# do some hard work here
if i % 10 == 0:
self.set_status_message("Progress: %d / 100" % i)
# displays a progress bar in the scheduler UI
self.set_progress_percentage(i)
Events and callbacks
Luigi has a built-in event system that allows you to register callbacks to events and trigger them from your own tasks. You can both hook into some pre-defined events and create your own. Each event handle is tied to a Task class and will be triggered only from that class or a subclass of it. This allows you to effortlessly subscribe to events only from a specific class (e.g. for hadoop jobs).
@luigi.Task.event_handler(luigi.Event.SUCCESS)
def celebrate_success(task):
"""Will be called directly after a successful execution
of `run` on any Task subclass (i.e. all luigi Tasks)
"""
...
@luigi.contrib.hadoop.JobTask.event_handler(luigi.Event.FAILURE)
def mourn_failure(task, exception):
"""Will be called directly after a failed execution
of `run` on any JobTask subclass
"""
...
luigi.run()
But I just want to run a Hadoop job?
The Hadoop code is integrated in the rest of the Luigi code because
we really believe almost all Hadoop jobs benefit from being part of some sort of workflow.
However, in theory, nothing stops you from using the JobTask class (and also HdfsTarget)
without using the rest of Luigi.
You can simply run it manually using
MyJobTask('abc', 123).run()
You can use the hdfs.target.HdfsTarget class anywhere by just instantiating it:
t = luigi.contrib.hdfs.target.HdfsTarget('/tmp/test.gz', format=format.Gzip)
f = t.open('w')
# ...
f.close() # needed
Task priority
The scheduler decides which task to run next from the set of all tasks that have all their dependencies met. By default, this choice is pretty arbitrary, which is fine for most workflows and situations.
If you want to have some control on the order of execution of available tasks,
you can set the priority property of a task,
for example as follows:
# A static priority value as a class constant:
class MyTask(luigi.Task):
priority = 100
# ...
# A dynamic priority value with a "@property" decorated method:
class OtherTask(luigi.Task):
@property
def priority(self):
if self.date > some_threshold:
return 80
else:
return 40
# ...
Tasks with a higher priority value will be picked before tasks with a lower priority value. There is no predefined range of priorities, you can choose whatever (int or float) values you want to use. The default value is 0.
Warning: task execution order in Luigi is influenced by both dependencies and priorities, but in Luigi dependencies come first. For example: if there is a task A with priority 1000 but still with unmet dependencies and a task B with priority 1 without any pending dependencies, task B will be picked first.
Namespaces, families and ids
In order to avoid name clashes and to be able to have an identifier for tasks, Luigi introduces the concepts task_namespace, task_family and task_id. The namespace and family operate on class level meanwhile the task id only exists on instance level. The concepts are best illustrated using code.
import luigi
class MyTask(luigi.Task):
my_param = luigi.Parameter()
task_namespace = 'my_namespace'
my_task = MyTask(my_param='hello')
print(my_task) # --> my_namespace.MyTask(my_param=hello)
print(my_task.get_task_namespace()) # --> my_namespace
print(my_task.get_task_family()) # --> my_namespace.MyTask
print(my_task.task_id) # --> my_namespace.MyTask_hello_890907e7ce
print(MyTask.get_task_namespace()) # --> my_namespace
print(MyTask.get_task_family()) # --> my_namespace.MyTask
print(MyTask.task_id) # --> Error!
The full documentation for this machinery exists in the task module.
Instance caching
In addition to the stuff mentioned above,
Luigi also does some metaclass logic so that
if e.g. DailyReport(datetime.date(2012, 5, 10)) is instantiated twice in the code,
it will in fact result in the same object.
See Instance caching for more info